Hadoop是使用Java编写,允许分布在集群,使用简单的编程模型的计算机大型数据集处理的Apache的开源框架。
Hadoop框架应用工程提供跨计算机集群的分布式存储和计算的环境。
Hadoop是专为从单一服务器到上千台机器扩展,每个机器都可以提供本地计算和存储。
Hadoop可运行于一般的商用服务器上,具有高容错、高可靠性、高扩展性等特点.特别适合写一次,读多次的场景
hadoop架构组成(粗略版本) Hadoop的架构,Hadoop主要有两个层次:加工/计算层(MapReduce),存储层(Hadoop分布式文件系统)。
The project includes these modules:
1 2 3 4 Hadoop Common: The common utilities that support the other Hadoop modules. Hadoop Distributed File System (HDFS™): A distributed file system that provides high-throughput access to application data. Hadoop YARN: A framework for job scheduling and cluster resource management.(分布式资源管理) Hadoop MapReduce: A YARN-based system for parallel processing of large data sets.
与 Apache Hadoop 的相关项目包括:
1 2 3 4 5 6 7 8 9 10 11 Ambari:一个基于Web 的工具,用于配置、管理和监控的 Apache Hadoop 集群,其中包括支持 Hadoop HDFS、Hadoop MapReduce、Hive、HCatalog、HBase、ZooKeeper、Oozie、Pig 和 Sqoop。Ambari 还提供了仪表盘查看集群的健康,如热图,并能够以用户友好的方式来查看的 MapReduce、Pig 和 Hive 应用,方便诊断其性能。 Avro:数据序列化系统。 Cassandra:可扩展的、无单点故障的多主数据库。 Chukwa:数据采集系统,用于管理大型分布式系统。 HBase:一个可扩展的分布式数据库,支持结构化数据的大表存储。(有关 HBase 的内容,会在后面章节讲述) Hive:数据仓库基础设施,提供数据汇总以及特定的查询。 Mahout:一种可扩展的机器学习和数据挖掘库。 Pig:一个高层次的数据流并行计算语言和执行框架。 Spark:Hadoop 数据的快速和通用计算引擎。Spark 提供了简单和强大的编程模型用以支持广泛的应用,其中包括 ETL、机器学习、流处理和图形计算。(有关 Spark 的内容,会在后面章节讲述) TEZ:通用的数据流编程框架,建立在 Hadoop YARN 之上。它提供了一个强大而灵活的引擎来执行任意 DAG 任务,以实现批量和交互式数据的处理。TEZ 正在被 Hive、Pig 和 Hadoop 生态系统中其他框架所采用,也可以通过其他商业软件(例如 ETL 工具),以取代的 Hadoop MapReduce 作为底层执行引擎。 ZooKeeper:一个高性能的分布式应用程序协调服务。
hadoop如何工作(入门理解版本)
建立重配置,处理大规模处理服务器这是相当昂贵的,但是作为替代,可以联系许多普通电脑采用单CPU在一起,作为一个单一功能的分布式系统,实际上,集群机可以平行读取数据集,并提供一个高得多的吞吐量。此外,这样便宜不到一个高端服务器价格。因此使用Hadoop跨越集群和低成本的机器上运行是一个不错不选择。
Hadoop运行整个计算机集群代码。这个过程包括以下核心任务由 Hadoop 执行:
1 2 3 4 5 6 7 8 数据最初分为目录和文件。文件分为128M和64M(128M最好)统一大小块。 然后这些文件被分布在不同的群集节点,以便进一步处理。 HDFS,本地文件系统的顶端﹑监管处理。 块复制处理硬件故障。 检查代码已成功执行。 执行发生映射之间,减少阶段的排序。 发送排序的数据到某一计算机。 为每个作业编写的调试日志。
hadoop 安装和配置入门
参见hadoop安装笔记另一篇
hadoop fs 查看相关用法
hadoop 操作模式,本地一般是模拟分布式模式
1 2 3 本地/独立模式:下载Hadoop在系统中,默认情况下之后,它会被配置在一个独立的模式,用于运行Java程序。 模拟分布式模式:这是在单台机器的分布式模拟。Hadoop守护每个进程,如 hdfs, yarn, MapReduce 等,都将作为一个独立的java程序运行。这种模式对开发非常有用。 完全分布式模式:这种模式是完全分布式的最小两台或多台计算机的集群。我们使用这种模式在未来的章节中。
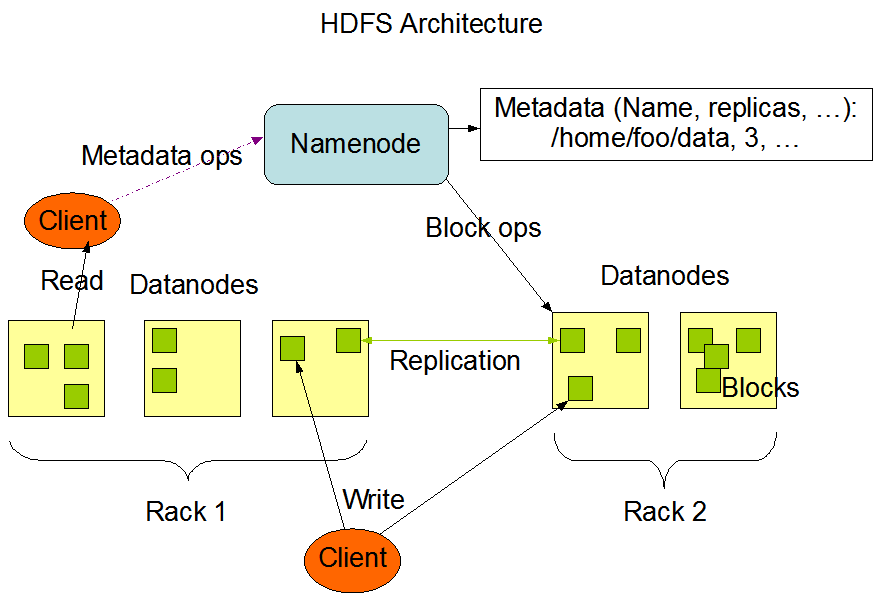
HDFS架构
HDFS遵循主从架构,从上图可以看出有nameNode和dataNode,block等组成
名称节点 - Namenode
1 2 3 4 5 名称节点是包含GNU/Linux操作系统和软件名称节点的普通硬件。它是一个可以在商品硬件上运行的软件。具有名称节点系统作为主服务器,它执行以下任务: 管理文件系统命名空间。 任何有关文件系统的改变都会被NameNode记录下来. 规范客户端对文件的访问。 它也执行文件系统操作,如重命名,关闭和打开的文件和目录。
1 2 3 Datanode具有GNU/Linux操作系统和软件Datanode的普通硬件。对于集群中的每个节点(普通硬件/系统),有一个数据节点。这些节点管理数据存储在它们的系统。 数据节点上的文件系统执行的读写操作,根据客户的请求。 还根据名称节点的指令执行操作,如块的创建,删除和复制。
1 一般用户数据存储在HDFS文件。在一个文件系统中的文件将被划分为一个或多个段和/或存储在个人数据的节点。这些文件段被称为块。换句话说,数据的HDFS可以读取或写入的最小量被称为一个块。缺省的块大小为64MB,但它可以增加按需要在HDFS配置来改变。
1 2 HDFS文件系统的元数据信息被存储在NameNode节点上.NameNode节点使用事物日志(叫做EditLog)来持久记录发生在文件系统上面每个变化,:创建文件会在EditLog中插入一条记录,改变副本因子也会新增一条新的记录.NameNode会使用本地文件系统来保存这个EditLog内容.整个HDFS文件系统的命名空间,数据块与文件的映射关系,文件系统的各个属性都被存放在一个叫做FsImage的文件中,这个FsImage文件也放在NameNode节点的本地文件系统中. NameNode会维护整个文件系统的命名空间和文件块的映射关系在内存中
HDFS的目标
故障检测和恢复:由于HDFS包括大量的普通硬件,部件故障频繁。因此HDFS应该具有快速和自动故障检测和恢复机制。
巨大的数据集:HDFS有数百个集群节点来管理其庞大的数据集的应用程序。
数据硬件:请求的任务,当计算发生不久的数据可以高效地完成。涉及巨大的数据集特别是它减少了网络通信量,并增加了吞吐量。
Moving Computation is Cheaper than Moving Data
HDFS常用命令
格式化配置HDFS文件系统,打开NameNode(HDFS服务器),然后执行以下命令。$ hadoop namenode -format
hadoop fs 或者hadoop fs -help