
SpringCloud Sleuth记录
- Spring Cloud Sleuth为Spring Cloud提供了分布式追踪方案
背景
- 对系统进行全链路的监控是非常有必要的。在单体应用中,传统的方式是软件开发者,通过自定义日志的level,日志文件的方式记录单体应用的运行日志。从而排查线上系统出现运行过慢,出现故障,异常等问题,但是在微服务架构或分布式系统中,一个系统被拆分成了A、B、C、D、E等多个服务,而每个服务可能又有多个实例组成集群,采用上诉定位问题的方式就行不通了,你充其量就知道某个服务是应用的瓶颈,但中间发生了什么你完全不知道。而且问题的查询,因为有海量各种各样的日志等文件,导致追溯定位问题等极其不方便。因此需要全链路监控系统的收集,上报,对海量日志实时计算生成,监控告警,视图报表,帮助开发人员快速定位问题。
服务追踪分析
- 一个由微服务构成的应用系统由N个服务实例组成,通过REST请求或者RPC协议等来通讯完成一个业务流程的调用。对于入口的一个调用可能需要有多个后台服务协同完成,链路上任何一个调用超时或出错都可能造成前端请求的失败。服务的调用链也会越来越长,并形成一个树形的调用链。
- 针对服务化应用全链路追踪的问题,Google发表了Dapper论文,介绍了他们如何进行服务追踪分析。其基本思路是在服务调用的请求和响应中加入ID,标明上下游请求的关系。利用这些信息,可以可视化地分析服务调用链路和服务间的依赖关系。
Spring Cloud Sleuth
- Spring Cloud Sleuth就是APM(Application Performance Monitor),全链路监控的APM的一部分,如果要完整的使用该组件需要自己定制化或者和开源的系统集成,例如:ZipKin。
- APM(Application Performance Monitor)这个领域最近异常火热,例如淘宝鹰眼Eagle Eyes,点评的CAT,微博的Watchman,twitter的Zipkin
- zipkin是基于goole的google-Dapper实现。
###ZipKin的架构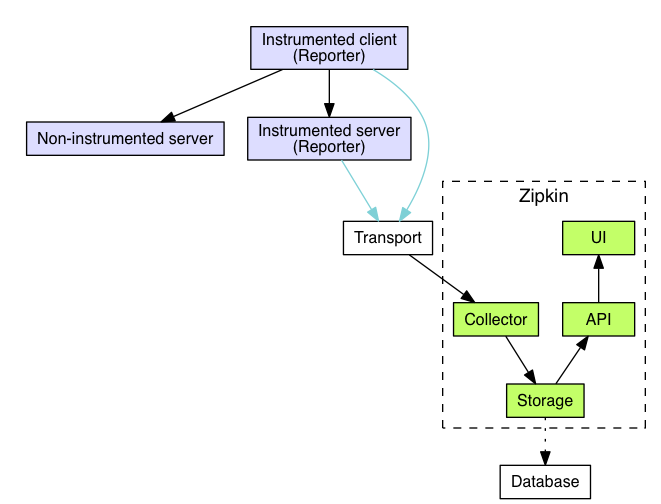
- collector 收集器
- storage 存储
- api 查询api
- ui 界面
####zipkin存储
- zipkin存储默认使用inMemory
- 支持存储模式
1 | inMemory |
####ZipKin数据模型
- Trace:一组代表一次用户请求所包含的spans,其中根span只有一个。
- Span: 一组代表一次HTTP/RPC请求所包含的annotations。
- annotation:包括一个值,时间戳,主机名(留痕迹)。
几个时间
- cs:客户端发起请求,标志Span的开始
- sr:服务端接收到请求,并开始处理内部事务,其中sr - cs则为网络延迟和时钟抖动
- ss:服务端处理完请求,返回响应内容,其中ss - sr则为服务端处理请求耗时
- cr:客户端接收到服务端响应内容,标志着Span的结束,其中cr - ss则为网络延迟和时钟抖动
H
