
hadoop mac上安装记录
hadoop 概述
- Apache Hadoop 的框架最核心的设计就是:HDFS 和 MapReduce。HDFS 为海量的数据提供了存储,而 MapReduce 则为海量的数据提供了计算。
引入
设想一下这样的应用场景。我有一个100M的数据库备份的sql文件。我现在想在不导入到数据库的情况下直接用grep操作通过正则过滤出我想要的内容。例如:某个表中含有相同关键字的记录那么有几种方式,一种是直接用linux的命令grep还有一种就是通过编程来读取文件,然后对每行数据进行正则匹配得到结果好了现在是100M的数据库备份。上述两种方法都可以轻松应对。
那么如果是1G,1T甚至1PB的数据呢,上面2种方法还能行得通吗?答案是不能。毕竟单台服务器的性能总有其上限。那么对于这种超大数据文件怎么得到我们想要的结果呢?
有种方法就是分布式计算,分布式计算的核心就在于利用分布式算法把运行在单台机器上的程序扩展到多台机器上并行运行。从而使数据处理能力成倍增加。但是这种分布式计算一般对编程人员要求很高,而且对服务器也有要求。导致了成本变得非常高。
Haddop就是为了解决这个问题诞生的。Haddop可以很轻易的把很多linux的廉价pc组成分布式结点,然后编程人员也不需要知道分布式算法之类,只需要根据mapreduce的规则定义好接口方法,剩下的就交给Haddop。它会自动把相关的计算分布到各个结点上去,然后得出结果。
例如上述的例子:Hadoop要做的事首先把1PB的数据文件导入到HDFS中,然后编程人员定义好map和reduce,也就是把文件的行定义为key,每行的内容定义为value,然后进行正则匹配,匹配成功则把结果通过reduce聚合起来返回。Hadoop就会把这个程序分布到N个结点去并行的操作。
那么原本可能需要计算好几天,在有了足够多的结点之后就可以把时间缩小到几小时之内。
这也就是所谓的大数据云计算了。如果还是不懂的话再举个简单的例子
比如1亿个1相加得出计算结果,我们很轻易知道结果是1亿。但是计算机不知道。那么单台计算机处理的方式做一个一亿次的循环每次结果+1
那么分布式的处理方式则变成我用1万台计算机,每个计算机只需要计算1万个1相加然后再有一台计算机把1万台计算机得到的结果再相加从而得到最后的结果。
理论上讲,计算速度就提高了1万倍。当然上面可能是一个不恰当的例子。但所谓分布式,大数据,云计算大抵也就是这么回事了。
一,安装和文件配置
brew install hadoop
编辑hadoop-env.sh (单机式)
在 /usr/local/Cellar/hadoop/2.8.2/libexec/etc/hadoop
1 | # export HADOOP_OPTS="$HADOOP_OPTS -Djava.net.preferIPv4Stack=true" |
- 编辑Core-site.xml (也在上个地址) ,贴入下方配置
1 | <configuration> |
- 编辑mapred-site.xml(也在该目录下,有模板文件,贴入如下配置)
1 | <configuration> |
- 编辑hdfs-site.xml(文件位置同上)
1 | <configuration> |
二, 配置环境
- vim ~/.bash_profile 添加配置(如果添加到.profile下则每次使用需要 source ~/.profile,推荐配置到./bash_profile 下)
- 配置完可以使用hstart 和hstop启动hadoop了(看下下边配置里hstart对应的相关启动sh)
1 | alias hstart="/usr/local/Cellar/hadoop/2.8.2/sbin/start-dfs.sh;/usr/local/Cellar/hadoop/2.8.2/sbin/start-yarn.sh" |
- 初始化Hadoop Cluster(在本地系统中format HDFS(Hadoop Distributed File System))
在hadoop-2.8.2路径里面运行
1 | $./bin/hdfs namenode -format |
- 允许远程登录
在“系统偏好”-> “分享” -> 打勾“远程登录”
(“System Preferences” -> “Sharing”-> “Remote Login”)
授权SSH Keys
要让电脑接收远程登录,就要先报备一下这个ssh key:
1 | $ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys |
试着登录一下:
1 | $ ssh localhost |
说明远程登录成功。好了,退出
1 | $ exit |
启动和关闭
1 | hstart |
查看是否启动成功
1 | 通过访问以下网址查看hadoop是否启动成功 |
三,运行demo
- 配置HDFS路径, hadoop-2.8.2路径里面运行
1 | $ bin/hdfs dfs -mkdir /user |
- Copy the input files into the distributed filesystem:(把本地 etc/hadoop 下的一些文件上传到 HDFS的 input 中)
1 | $bin/hdfs dfs -put libexec/etc/hadoop input |
- 执行,在上传的数据中使用 MapReduce 运行 grep, 计算以dfs开头的单词出现的次数,结果保存到 output 中。
1 | $bin/hadoop jar libexec/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.8.2.jar grep input output 'dfs[a-z.]+' |
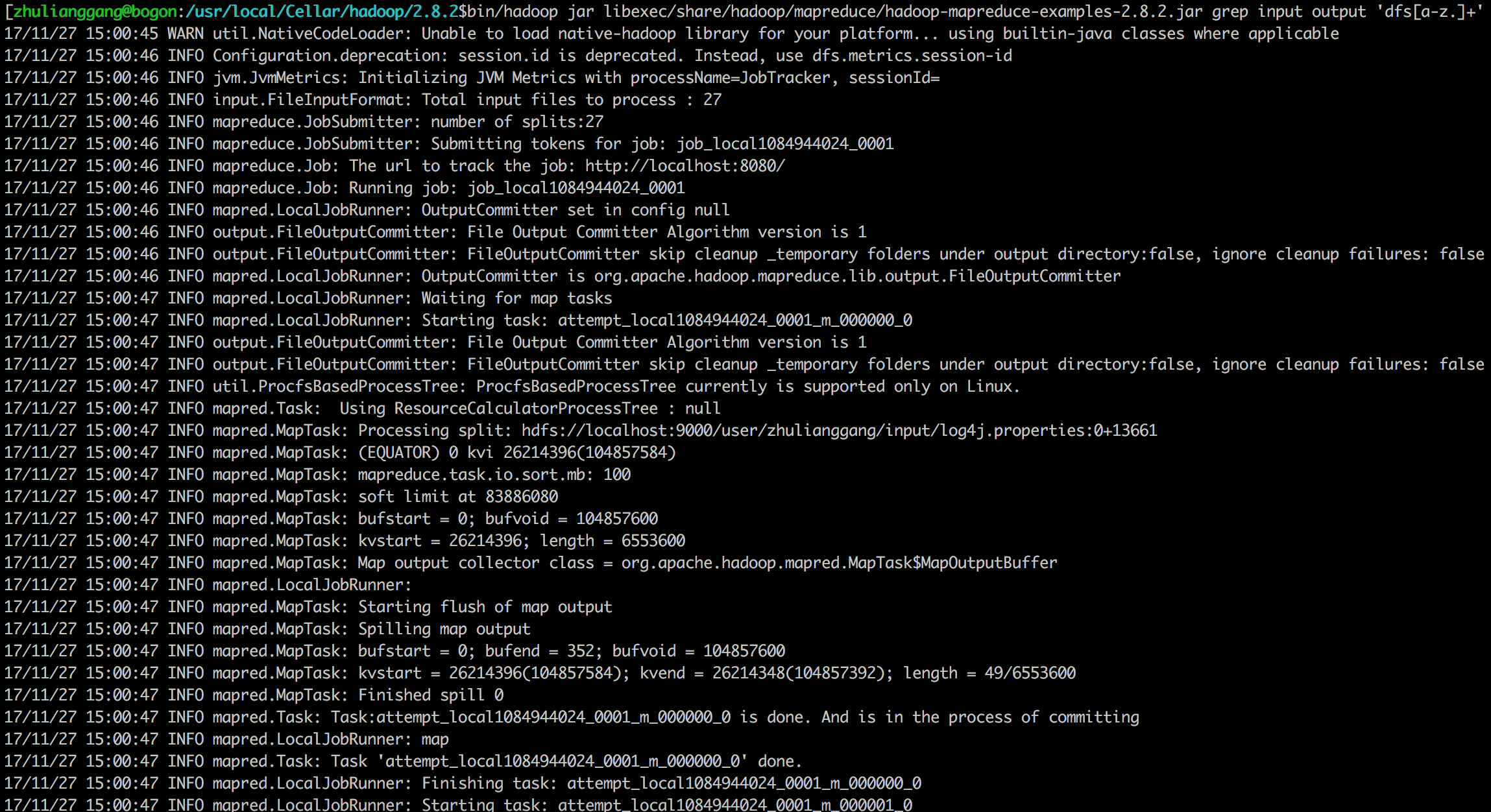
- 查看
1 | $ bin/hdfs dfs -cat output/* |
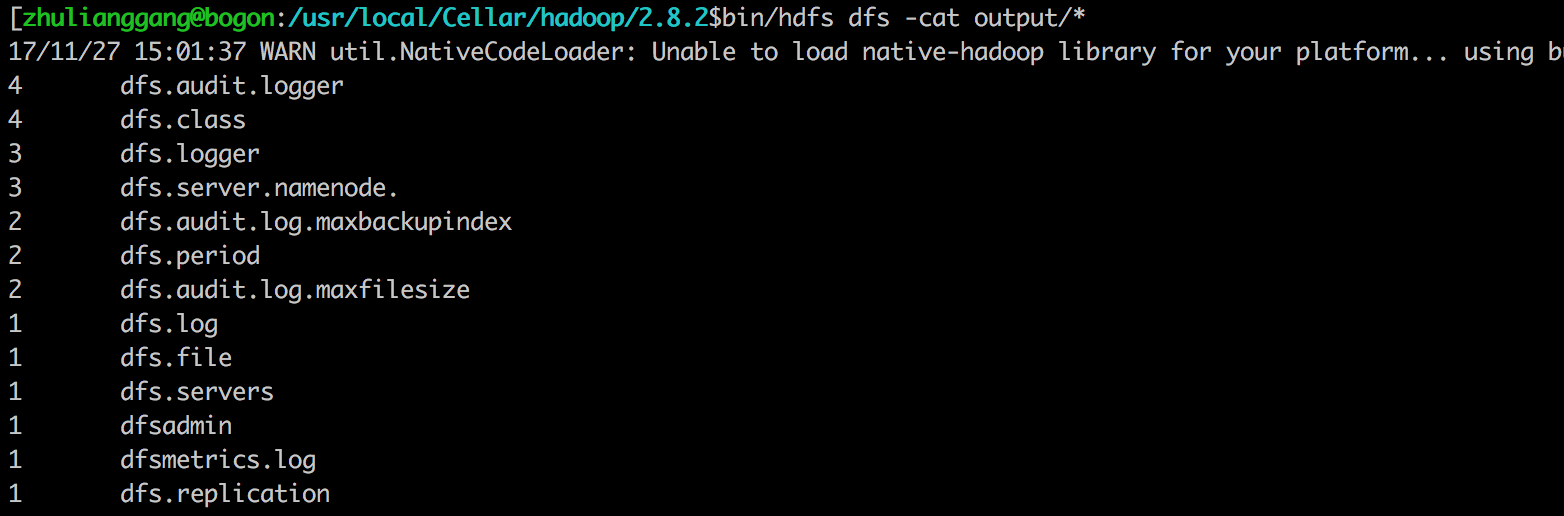
通过web也查看结果

mac 上下载结果是出现无法下载http://bogon:50075/xxxxx,替换bogon为localhost
